MemOS: An Operating System forMemory-Augmented Generation (MAG) in LargeLanguage Models (Short Version)
Part1 核心内容
LLMs的记忆受限于参数化的、短期的内存,知识演化和迭代能力受到了制约。本文引入了MemOS——一个专为LLMs设计的内存操作系统,首次将内存提升为一级操作资源。
就是把原来模糊不清、散乱的大模型“记忆”用了一个系统来明确地管理。
Part2 深入探究
2.1 方法论
对于记忆系统的探索
step1 一般的分类:隐式记忆和显式记忆、短期和长期
隐式记忆:模型权重、推理过程中的缓存
显式记忆:上下文(短期)、类似RAG的外部检索(长期)
step2 类人记忆模式
step3 系统化记忆管理
———得到了我们的牛b系统,记忆大一统。
Q:但是这样本质上不是还是原来的这些记忆方式和记忆编辑手段吗?有什么新意吗?发现其实没有。
MemOS将内存分为三种核心类型:参数化内存(Parametric Memory)【包括可插拔的LoRA模块】、激活内存(Activation Memory)【可持久化???】和明文内存(Plaintext Memory)
2.2 模型架构
引入MemCube作为封装单元。(可以类比消息)
结构分为Header、Payload,以及一些其他的有关访问控制的属性。(行为指标)
框架分为Interface Layer(输入)、Operation Layer(执行)、Infrastructure Layer(基本架构)
AGENT KB: Leveraging Cross-Domain Experience for Agentic Problem Solving
Part1 核心内容
给出一种新框架AGENT KB,让agent可以学习、提炼以往经验(更高层面,而不只是局限于某一特定的任务),实现经验知识在智能体之间的传递。
Part2 深入探究
2.1 方法论
构建共享的知识库,捕捉高层次的解决问题策略及详细的执行教训,从而实现知识在不同框架内智能体之间的传递。
Reason-Retrieve-Refine(推理、检索、精炼)流水线,teacher-student检索机制。学生首先检索工作流程级别的模式来构建其方法,而教师随后识别特定的执行模式来优化实现细节(实现监督)。这两个智能体都是为最后执行智能体服务的。
先通过任务池提取经验,构成经验库。然后在推理中进行检索和应用。
当前agent系统的三大缺陷:
1.agent对于不同类型任务的经验是孤立的,没有很好的泛化性。(没有办法迁移)
2.agent检索问题时没有一个序列化的推理优化。
3.agent的经验形式太垂直?(从经验保存的角度来看,比如对于某一专业领域的经验,没有经过抽象,太难迁移)
2.2 模型架构
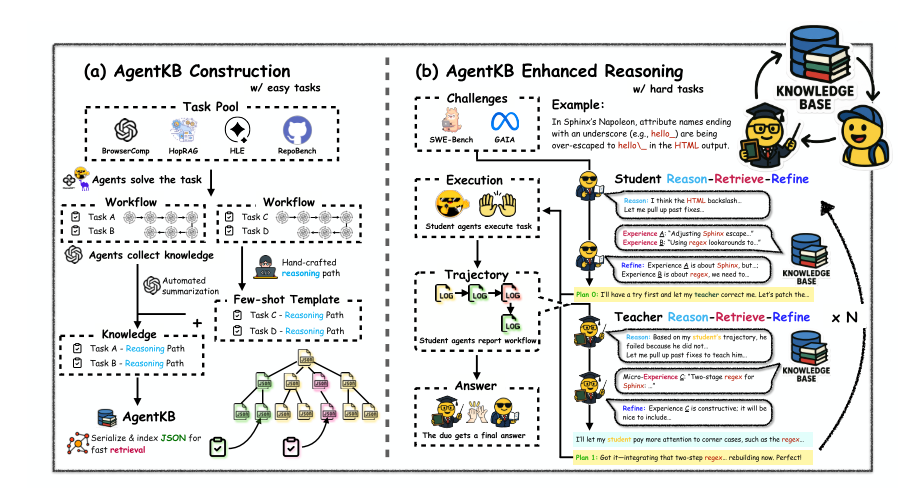
对于这两种智能体,实际上都有RRR的流程。
学生智能体的核心功能是生成符合任务需求的初始规划,流程包括:
- 问题解析 提取任务的问题模式($\hat{\pi}$)和目标($\hat{\gamma}$),生成初步解决思路($\tau$);
- 经验检索 从 AGENT KB 中检索与任务匹配的工作流级经验($\mathcal{E}_w$),公式为:
$\mathcal{E}_{w} = \underset{\mathcal{E}_{i} \in \mathcal{K}}{top-k}\left[\alpha \cdot \phi_{r}\left(\mathcal{E}_{i}, \mathcal{T}, \hat{\pi}, \hat{\gamma}\right)\right]$其中$\phi_r$衡量经验与任务的相关性,$\alpha$为权重; - 方案优化 检索到的经验与初始思路整合,生成结构化执行计划($\Pi$)并执行,输出执行轨迹(S)。
学生智能体的重点是确保任务解决的整体框架合理,例如工具选择、步骤顺序等策略层面的正确性。
教师智能体的核心功能是优化学生的执行细节,流程包括:
- 轨迹分析 总结学生的执行轨迹($Z = \text{SUMMARIZE TRAJECTORY}(S)$),识别错误类型及原因;
- 精准检索 从 AGENT KB 中检索与错误步骤匹配的步骤级经验($\mathcal{E}_s$),公式为:
$\mathcal{E}_{s} = \underset{\mathcal{E}_{j} \in \mathcal{K}}{top-m} \sum_{s_{i} \in \mathcal{Z}}\left[\alpha \cdot \phi_{r}\left(s_{i}, \mathcal{S}_{j}\right)\right]$其中$\phi_r$衡量步骤与经验的相似度; - 指导生成 将检索到的经验适配到当前场景,生成具体修正建议($\Gamma$),指导学生优化执行。
教师智能体的重点是修正执行中的细粒度问题,例如参数配置、错误处理、工具使用细节等,提升任务解决的精度。
2.3 实验设计
测试在GAIA(通用助手)与SWE-bench(软件工程)两个基准测试上展开。对于这两个测试,分别使用SmolAgents和Openhands框架。
AGENT KB构建的知识库来源:
对于通用助手任务,BrowseComp[43](1,266个任务),HopRAG[44](2,556个任务),HLE[45]的一个文本子集(3,000个任务)和WebWalkerQA[46](680个任务)。
经验库构造格式实例
{
"question": "有一个获得多项格莱美奖的知名人物……",
"true_answer": "St. John’s Health Center(圣约翰健康中心)",
"agent_planning": "1. 解析问题,提取所有关键约束条件:获得多项格莱美奖,第一张专辑发行于1969年之前,有药物依赖问题,20岁前被学校开除,第一位人生伴侣于1997年去世,曾作为军装人员服役,确定死亡地点/医院。\n2. 概念性规划:\n- 确定所有符合以上条件的艺人候选人。\n- 对每位候选人:\n a) 验证首张专辑发行时间(1969年之前)\n b) 检查格莱美获奖历史\n c) 检索传记资料,确认药物依赖与教育背景\n d) 确认伴侣去世年份和军装服役信息\n e) 锁定匹配人物的死亡日期和具体地点/医院。",
"search_agent_planning": "1. 从代码代理处获得精确的人物身份,或利用传记线索进行三角定位。\n2. 制定搜索查询,确认人物身份及其具体去世医院。\n3. 优先查找官方传记、权威新闻媒体、格莱美官方记录。\n4. 交叉核查关键信息点,确保人物匹配。\n5. 从讣告中提取死亡地点和医院信息。",
"agent_experience": [
"将复杂多条件问题拆分为小型约束检查",
"明确记录并多渠道验证传记约束条件",
"优先选用高可靠性传记和奖项数据来源",
"在早期将具体子查询委托给搜索代理",
"通过依次回链所有事实,最终验证答案"
],
"search_agent_experience": [
"将复杂查询分解为连续的搜索细化步骤",
"为模糊身份设计高度具体的检索关键词",
"优先使用权威信息源而非娱乐/八卦内容",
"从多方独立来源交叉验证信息",
"直接引用和明确来源,规范化结果格式"
]
}
对于软件工程知识,RepoClassBench[47],SWE-Gym-Raw[48]和RepoEval[49],总共包含约3,000个结构化问题解决轨迹。
评估的LLMs包括GPT-4o(2024-11-20)、GPT-4.1(gpt-4.1-2025-04-14)、Claude-3.7(sonnet-20250219)、o3-mini(o3-mini-2025-01-31)、Qwen-3 32B和DeepSeek-R1。在所有实验中,top_k设置为0.1,温度设置为1.0。
-
+AGENT KB:学生代理尝试一次,教师代理提供反馈 -
+AGENT KB ✓:Pass@2,两次尝试选最佳 -
+AGENT KB ✓♡:Pass@3,三次尝试选最佳(对标SOTA)
2.4 结果分析
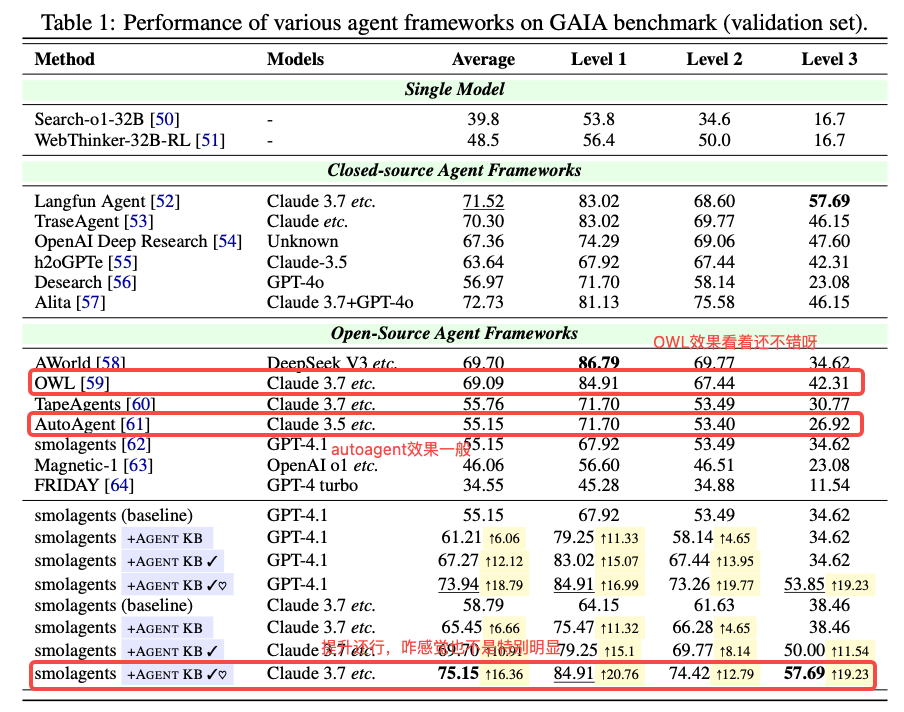
为什么Level3没有动?
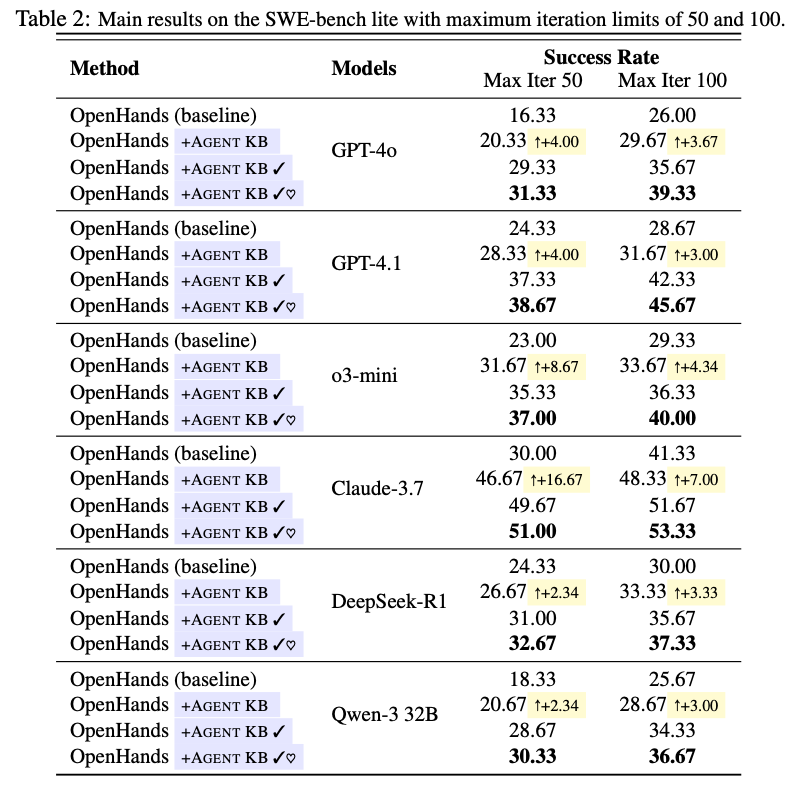
消融实验:
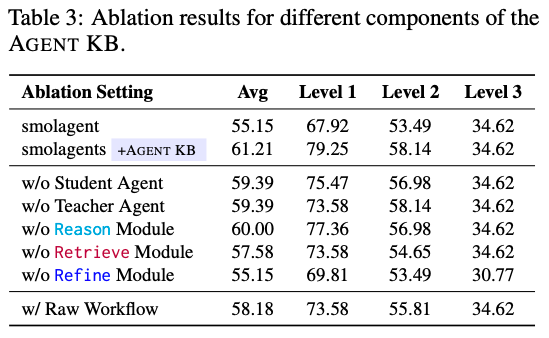
可以看出这个框架效果还是很好的
SkillWeaver: Web Agents can Self-Improve by Discovering and Honing Skills
Part1 核心内容
提出了一个三阶段的网页Agent自我改进框架SkillWeaver,通过自动合成API使Agent能够自主发现和改进其技能。三个阶段:技能提议、技能合成和技能精进。这些阶段利用LLMs的反馈能力迭代地完善探测的网站环境的技能。
Part2 深入探究
2.1 方法论
让网页Agent自己给自己生成API,充实“技能库”,从而达成Agent的自我升级与迭代。
2.2 模型架构
| 阶段 | 名称 | 功能描述 |
|---|---|---|
| Stage I | Skill Proposal(技能提议) | LLM根据网页结构和已有技能,提出新的可学习任务(如“搜索药品”、“筛选商品”)。 |
| Stage II | Skill Synthesis(技能合成) | Agent尝试执行任务,成功后将其封装为python的API,并附带文档和使用日志。 |
| Stage III | Skill Honing(技能精进) | 自动生成测试用例,反复验证API,失败则调试修正。 |
可以理解为每个技能是一个轻量的Python函数,封装了一些网页的交互流程。
这些技能(API)可被即插即用,无需重新训练模型。
2.3 结果分析
docker测试网站(WebArena):
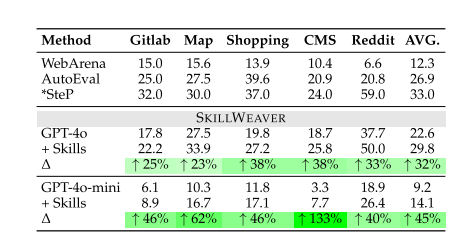
真实网站:
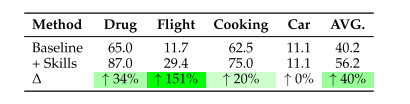
文中这句话如果成立,则应当是说,原WebArena采用的也是GPT-4o,而使用了SkillWeaver的GPT-4o-mini超越了此基线。
感觉好像不太对?

下面这段话的数据也不知从何而来。这篇论文中的数据似乎不太完善,不过思想是比较经典的,有点类似我的大作业。

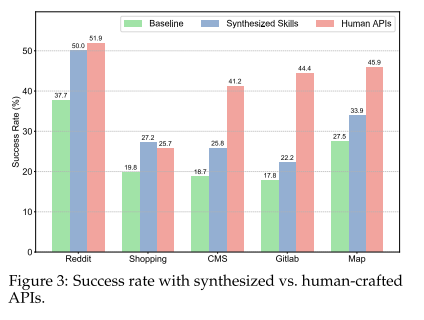
API的执行可行性还是不错的
Mobile-Agent-E: Self-Evolving Mobile Assistant for Complex Tasks
Part1 核心内容
与上一篇相比,这一篇主要是在移动领域应用的Agent自进化。对类似手机AI助手之类的应用开发应当有启发价值。
实际上回答了以下几个问题:
- 如何使智能助手具备自我学习和改进的能力?
- 如何设计一个能够处理复杂任务的移动Agent?
- 如何评估移动Agent在真实场景中的性能?
Part2 深入探究
2.1 方法论
提出了Mobile-Agent-E。它是一个分层多Agent框架,可以实现自我进化。它将高层计划与低层行动执行明确分开,并导入了自我进化模块,可从过去经验中学习可重用的部分。
2.2 模型架构
多层架构
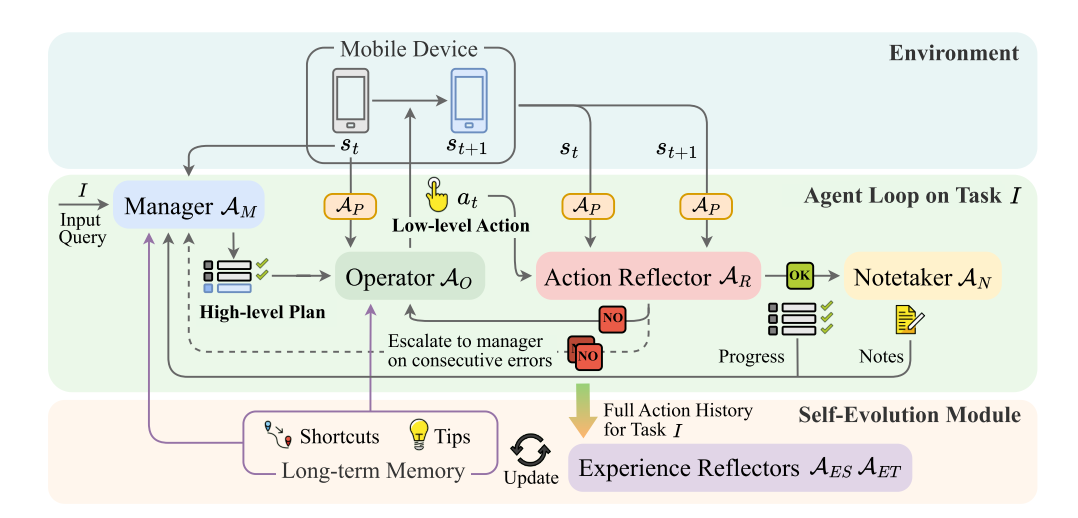
具体来说,Mobile-Agent-E由一个“上级”管理者和四个“下级”助手组成。(所谓的高层计划、低层行动)
管理者 一个基于大型多模态模型的推理Agent,用于为用户的请求创建包含分解子目标的高层计划。管理者还会参考长期记忆中的可用捷径(Shortcuts)来指导规划。此外,当模型观察到连续的动作失败时,会触发错误上报(Error Escalation),通知管理者检查最近的错误并决定高层次的调整以解决问题。在其他情况下,当错误首次发生时,操作员(Operator)会先尝试解决问题,只有在无法解决时才将问题升级给管理者。
感知者 一个基于纯视觉的感知模块。用于检测当前截图中细粒度的文本和图标信息。Perceptor包含三个子模块:OCR模型、图标识别(icon recognition)模型和图标描述(icon captioning)生成模型。
(纯视觉情况下,感觉上限太低了。)
操作员 一个基于LMM的推理代理,用于根据管理者提供的高层计划决定下一步即时动作(例如 点击 Tap(x, y))。操作员还会参考长期记忆中的提示(Tips)来指导决策。动作空间不仅包含原子操作(Atomic Operations),还包括捷径(Shortcuts)。关于Tips和Shortcuts会在后文详细阐述。
动作反思者 是基于LMM的推理代理,用于通过比较动作前后的截图验证前一个动作是否达到预期结果。如果动作成功,动作反思者会记录当前的任务进展;如果动作失败,则提供额外的错误反馈。
记录员 是基于LMM的推理代理,用于在任务导航过程中记录并汇总重要信息。例如,商品价格或餐馆的电话号码。
自进化模块
另外一个很重要的创新点是自进化模块。
核心组成如下:
- Long-term Memory。存储两种关键知识 ——
Tips(通用指导)和Shortcuts(捷径),且知识会随任务执行不断更新。 - Experience Reflectors。包含两个专用 Agent,分别负责更新
Tips($A_ET$)和Shortcuts($A_ES$),基于过往任务的交互历史生成新的或优化已有知识。
Tips更新:
$L_T = \mathcal{A}_{ET} \left( I, W_P^\tau, W_G^\tau, W_A, W_E, T_F, L_T \right)$
含义:A_ET根据当前任务的查询($I$)、最终计划($W_P^τ$)、进度($W_G^τ$)、行动历史($W_{A}$)、错误历史($W_E$)、未来任务($T_F$)和现有 Tips($L_T$),输出更新后的 Tips 集合($L_T$)。
Shortcuts更新:
$L_{S}= \mathcal{A}_{ES}\left( I, W_{P}^{\tau}, W_{G}^{\tau}, W_{A}, W_{E}, T_{F} , L_{S}\right)$
含义:A_ES基于与A_ET相同的输入(替换为现有 Shortcuts $L_S$),输出更新后的 Shortcuts 集合($L_S$)。
2.3 实验设计
构建了新的benchmark:Mobile-Eval-E
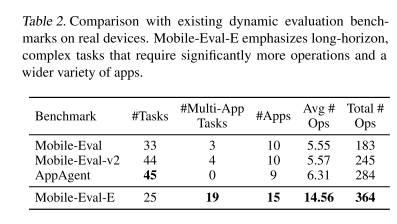
相较于原来的Benchmark,在难度上有了很大提升。
主要实验结果
可见分层Agent架构和进化模块的效果都很好
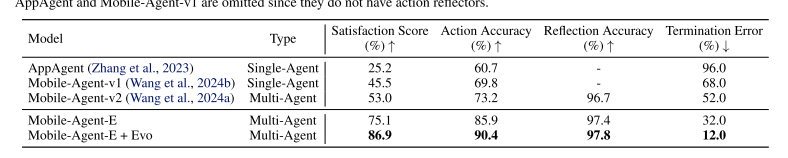
此外还进行了跨模型验证、效率分析、消融研究等,暂且不表。关于实验部分,AGENT-KB那篇文章是很好的,可以参考那一篇文章的叙述。感觉这几篇文章在这方面都差别不大。
实验上还有几个结论:
1.进化存在渐进性。任务越靠后,性能提升越明显。
2.Shortcuts的稳定性有待提高,可能存在误用或是错误。
Optimizing Model Selection for Compound AI Systems
Part1 核心内容
这篇的想法其实与我之前做的那个项目也很像。对于不同的模块,其实可以分配不同的LLM,节省资源,优化响应速度,提高性能。
本文提出了LLMSELECTOR框架,能够在有限的API调用预算下,迭代选择和分配性能最佳的模型,实现高效的模型选择。
但是本文是基于性能优先选择的,且是静态而非动态的!
Part2 深入探究
2.1 方法论
本文框架基于两个关键的假设:
一是系统的端到端性能通常在各模块性能持平的情况下是单调的;
(什么意思?——系统是简单的。如果某模块性能提升,总性能也会提升;系统是稳定的。模块性能持平的前提下,系统性能的变化是可预测的。)
二是模块性能可以通过LLM准确估计。
(为什么要估计?——让框架知道哪个模型在特定模块上表现最好,从而做出最佳选择。)
基于此,本文的框架通过迭代方式为每个模块分配表现最佳的模型,直至无法获得更多性能提升。
2.2 模型架构
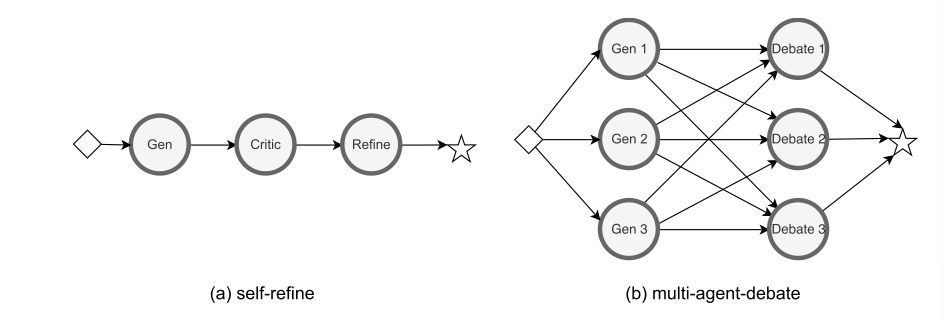
本文假设复合的静态AI系统为一个有向无环图,每一个节点都表示一个(LLM)模块。如下图为两个简单的静态AI系统示例。
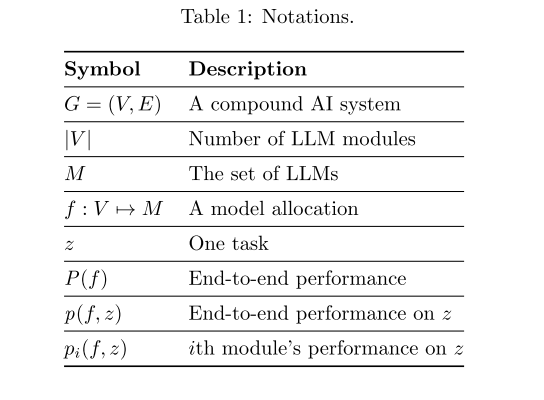
如下表规定了一些系统建模的定义,值得关注的是与P相关的。
$P(f)$即为给定模型下,分配f后,端到端的性能。我们就是要让$P(f)$尽可能高。
显然,不可能穷尽搜索所有可能的模型分配,因为其搜索空间会随着模块数量的增加呈指数级增长,这是一个NP问题。
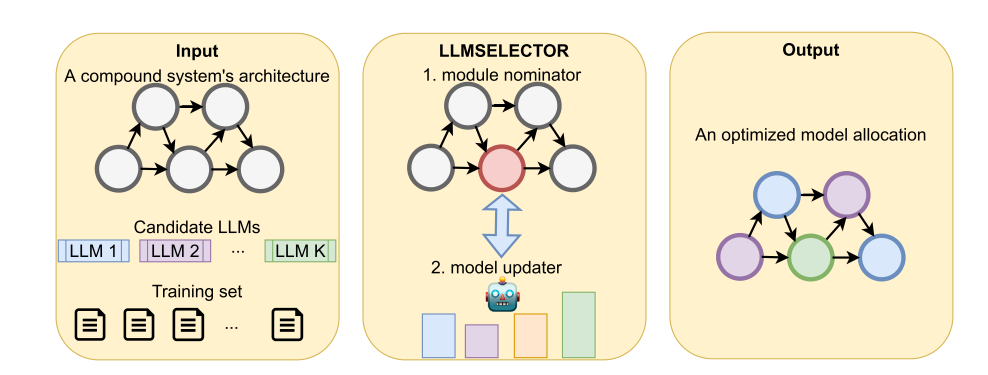
在具体的优化实现层面,如下图。
模型输入:一个复合AI系统,一组待分配的LLM,一些训练数据集,一个预算上限。
优化选择:框架迭代选择一个模块,并将其分配给通过LLM估计的模块性能最高的模型。(Repeat,直到达到性能或预算上限)
返回结果:框架返回一个优化的模型分配。

解析这个算法(懒得敲了,贴一下AI的结果):
| 行号 | 原文 | 解析 |
|---|---|---|
| 1 | Choose a random f0 ∈ F | 随机初始化一个模型分配方案 f0,即给每个样本 z 随机指派一个模型 k ∈ M。 |
| 2 | i ← 1, c ← 0, done ← False, f ← f0, ∀z ∈ DTr | 初始化迭代计数器 i、已消耗预算 c、终止标志 done、当前方案 f。 |
| 3 | while c ≤ B − M and done = False do | 只要预算未耗尽且未达到停止条件,就继续循环。 |
| 4 | j ← i mod L + 1 | 通过模运算,轮流选择第 j 个模块(1…L 循环)。 |
| 5 | $k_z ← max_{k∈M} Πi(f_{z,j→k}, z)$ | 对于训练集中的每个样本 z,把第 j 个模块的模型换成 k,评估新方案$f_{z,j→k}$对 z 的效果,选出使$Πi$ 最大的 k。 |
| 6 | fz ← fz,j→k | 真正地把样本 z 在第 j 个模块上的模型更新为刚选出的最优 k。 |
| 7 | f_i ← mode({fz : z ∈ DTr}) | 对所有样本在第 j 个模块上的最新模型做“众数/多数表决”,得到第 j 个模块的统一模型选择(减少碎片化)。 |
| 8 | c ← c + M | 更新已消耗预算。 |
| 9-11 | if i > L and Π_{i−L}(f) = Πi(f) then done ← True | 如果连续 L 次迭代性能都没有提升,则提前终止。 |
| 13 | return f | 返回最终优化后的模型分配方案 f。 |
所以就可以这么理解:
- 每个模块会遍历训练集:算法通过 “模块提名”(步骤 4:j \= i mod L + 1)轮流选中每个模块进行优化,每次选中模块 j 后,会遍历训练集内的所有任务 z(步骤 5-6),为每个 z 确定能最大化模块 j 性能的模型,进而更新该 z 的分配方案(仅调整模块 j 的 LLM,其他模块保持不变)。
- 更新标准是模块性能最高:对于当前选中的模块 j,针对每个任务 z,从候选 LLM 中选择能使模块 j 性能(pj)达到最高的模型 kz(步骤 5:kz \= maxk∈M pj (fz,j→k, z)),并将该模型分配给模块 j,完成对 z 的分配更新。
作为对比,普通的贪心算法是说:
迭代地选择一个模块,并为其分配能使系统端到端性能达到最高的模型。
具体来说,这种贪心算法每次只关注整体系统的最终表现,当为某个模块更换模型时,只有在这种更换能直接提升整个系统的端到端性能时,才会采纳该模型;如果更换模型后,端到端性能没有提升,即使该模型在模块级性能上更优,也不会被选择。
文中给出了一个例子。在TableArithmetic数据集上,当贪心算法遇到将GPT-4o mini分配给两个模块这一 “局部最优” 方案时,由于单独更换任何一个模块的模型都无法提升端到端性能,它就会停滞在该方案,无法继续搜索到更优的全局分配。
这里就呼应了一开始的两个假设,它们保证了这种“模块最优即全局最优”的想法是正确的。
一是系统的端到端性能通常在各模块性能持平的情况下是单调的;
二是模块性能可以通过LLM准确估计。
当然,实际系统自然不太可能一直满足这些假设(尤其是第一条)。不过本文也给出了说明,推导出的算法仍然适用实际情况,并表现出较好的性能。
有关“性能”的衡量,文中设置了一个LLM诊断器,用这个LLM去给分配的结果打分。这里诊断器的有效性是依托假设二成立的。这里需要得到说明和补充,可能存在创新点?
但是这个论文的意义可能在于,依托这个假设构造的框架,在实际的实验上表现良好。有点黑箱的意思。

2.3 实验设计
实验的主要内容有以下三·点:
验证为复合AI系统的不同模块分配不同LLM能否显著提升性能;
验证使用基于模块最优的分配方法能否显著提升性能;
量化框架带来的性能增益。
复合AI系统
主要是上面提到的3类典型复合系统。(还有一类是简单的分析-解答,两个节点)
数据集
|6 个数据集
||||
|数据集|任务类型|规模|评估指标|
| -----------------------------------------| ------------------------------------| ----------------------| ------------------------------|
|TableArithmetic|表格任务提取与算术解答|100 个样本|精确匹配(是否正确)|
|TableBias|表格任务提取与逻辑推理|100 个样本|精确匹配|
|LiveCodeBench|代码输出预测|479 个样本|精确匹配(代码输出)|
|CommonGenHard|约束概念生成连贯文本|200 个样本|概念覆盖率(是否含所有概念)|
|SimpleQA|事实性问答|4326 个样本|精确匹配(答案正确性)|
|FEVER|事实验证(支持 / 反驳 / 信息不足)|2384 个样本|精确匹配(分类正确性)|
LLM
使用10个主流LLM,包括闭源模型(如 GPT-4o、Claude 3.5 Sonnet、Gemini 1.5 Pro)和开源模型(如 Llama 3.1 405B、Qwen 2.5 72B)。
对比方法
1.对比单一模型,为所有模块分配同一 LLM(如 GPT-4o、Claude 3.5 Sonnet 等);
2.对比其他优化方法,如DSPy(专注于提示词优化,使用 MIPROv2 优化器);
3.对比其他分配LLM方法,如随机尝试模型分配、贪心搜索(迭代选择提升总体端到端性能的模型)。
2.4 实验结果
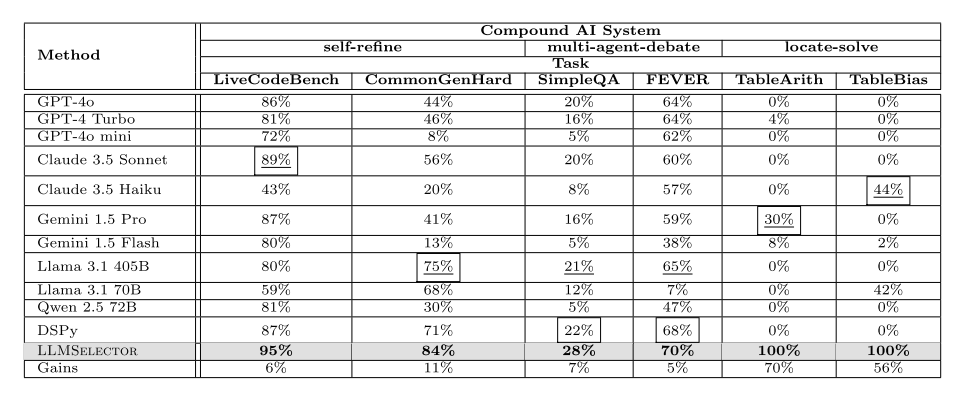
性能显著优!且在表格类任务(TableArithmetic、TableBias)中增益最显著,因这类任务的模块分工明确,不同LLM的优势差异大。
这个实验结果还是很令人振奋的,而且显示了垂直类模型、轻量级模型的潜力。参数量大的模型也并不是包打天下的。
MAS-GPT: Training LLMs to Build LLM-based Multi-Agent Systems
Part1 核心内容
对于多智能体系统的构建,本文探讨了如何以最低成本自适应地构建针对查询的MAS。具体而言,就是训练了一个MAS-GPT模型,可以根据需求来构建相对应的多智能体系统。
MAS的构建重新表述为生成性语言任务,该任务的输入为用户查询,输出为相应的MAS。
Part2 深入探究
2.1 方法论和模型的架构
采用Python代码片段来统一表示MAS,把每个智能体的提示视为变量、LLM调用视为函数、智能体间关系通过字符串连接表示。
在数据集构建过程中,采用包含构建、评估、选择和优化的步骤来形成高质量的查询-MAS对,以提高模型学习通用模式和逻辑相关性的能力。经过监督微调训练后,构建的MAS-GPT模型具备生成与具体查询对应的MAS的能力。
构建查询池+构建多智能体系统池+配对+评估
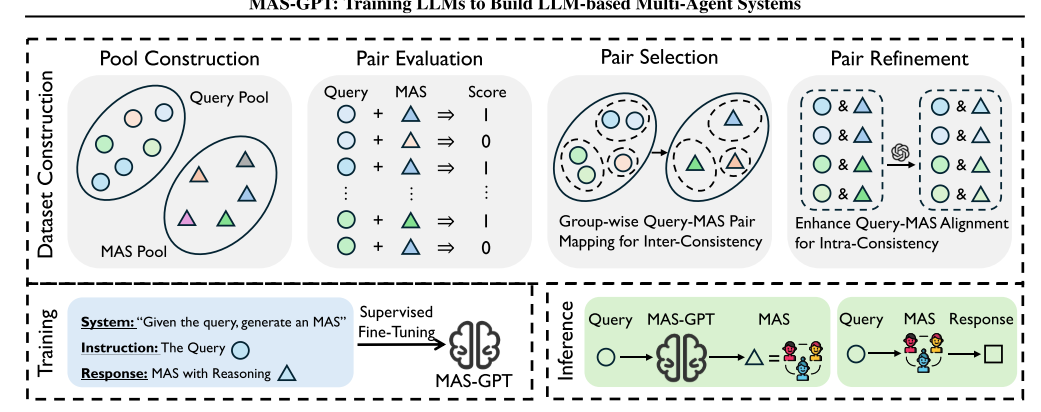
在配对中有两个special的处理方式。
第一,因为类似的或是相同的查询可能对应不同的MAS,这对模型训练不利。所以在选择的时候,对查询进行聚类,对每类查询,选择一个最佳的MAS。这样可以提高查询-MAS对的一致性,有助于模型学习识别可泛化的模式,并在相似查询之间进行泛化。
第二,在查询-MAS对里,可能存在内部“不一致”的情况。也就是查询内容和MAS之间的关联性不强,这样模型可能会混淆。所以作者通过两个策略来改进查询-MAS的对齐。第一是让LLM根据查询和先前选择的MAS调整MAS中AGENT的定义(与查询强相关)。第二是让LLM生成一个推理陈述(也就是解释一下),解释查询和优化后的MAS之间的关系,从而提高查询-MAS对的可解释性。这也是为了提高泛化能力。
2.2 实验设计与结果分析
训练样本(查询 - MAS对)约11k,来自多个开源数据集,涵盖数学(MATH、GSM8K)、编码(MBPP)、通用问答(MMLU、SciQ)等领域,确保查询可验证(有标准答案或测试用例)。
9个多领域基准测试,包括:
- 数学:MATH、GSM8K、GSM-Hard;
- 编码:HumanEval、HumanEval+;
- 通用 QA:MMLU、GPQA、SciBench;
- 高难度数学:AIME2024。
其中部分基准(如 GPQA、SciBench)为 “域外(out-of-domain)” 测试,验证泛化能力。
5个主流 LLM,包括开源模型(Llama-3-70B-Instruct、Qwen2.5-72B-Instruct)和闭源模型(GPT-4o-mini、o1-preview、DeepSeek-R1),验证MAS-GPT与不同LLM的兼容性。
基线方法:10+种多智能体或单智能体方法,包括:
- 单智能体:Single(直接用 LLM 回答)、Chain-of-Thought(思维链);
- 多智能体:Self-Consistency(自一致性)、LLM-Debate(辩论)、Self-Refine(自优化)、AgentVerse、GPTSwarm、DyLAN等。
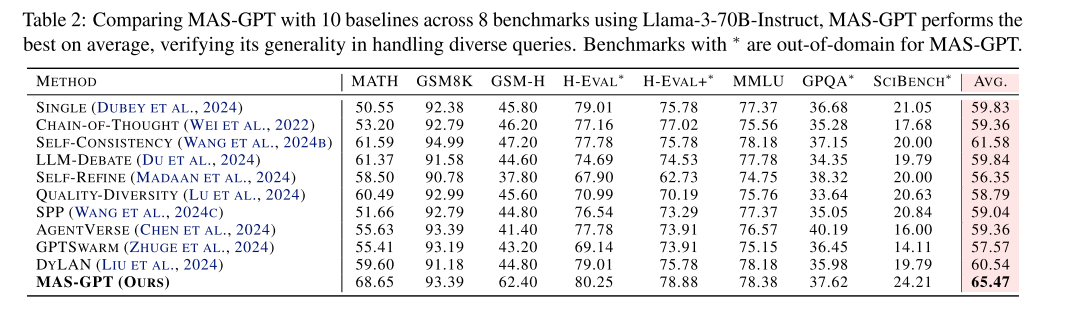
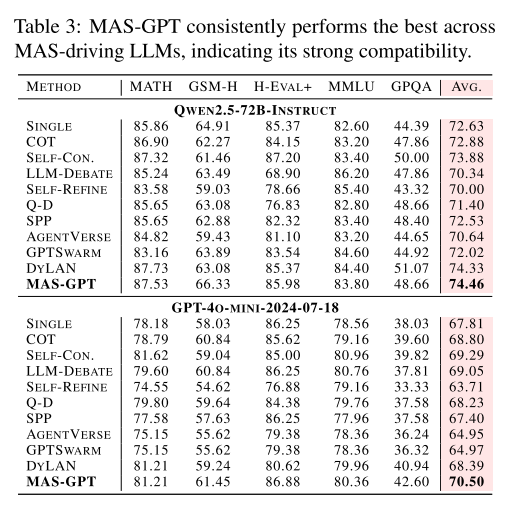
可见,这种方法在有效性、泛化能力上都有提升。
消融实验:

可见,数据构建中三个核心步骤都有正向作用。两个一致性模块均对性能有提升。
这个是训练了三次的结论吗?
AUTOMATED DESIGN OF AGENTIC SYSTEMS
Part1 核心内容
这篇也是讲自动化生成Agent系统,和前面的MAS-GPT有点相似。提出了基于“Meta Agent Search”的ADAS框架。定义了三大组件:搜索空间(可被发现的智能体系统范围)、搜索算法(探索搜索空间的方法)和评价函数(衡量智能体性能的指标)。核心是让元智能体(meta agent)基于历史的代码存档迭代编程新智能体。(这里智能体也是以代码的形式)
Part2 深入探究
2.1 方法论和模型的架构
三大组件:搜索空间(可被发现的智能体系统范围)、搜索算法(探索搜索空间的方法)和评价函数(衡量智能体性能的指标)
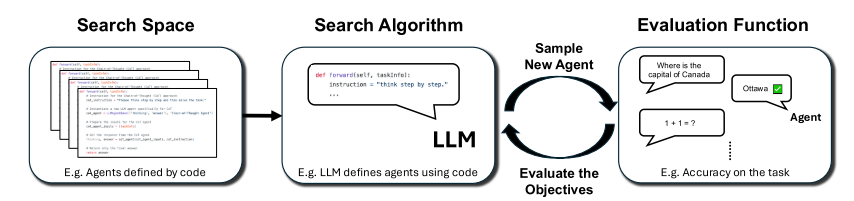
ADAS的算法:
(1)初始化存档(也就是基础的代码)。包含手动设计的基础智能体(如思维链、自我反思)。
(2)设计新智能体。元智能体基于存档生成新智能体的代码,通过两轮自我反思确保新颖性和正确性。
(3)评估与精炼 。 在目标领域验证新智能体,若出错则最多精炼5次。
(4)更新存档,将通过评估的智能体及其性能指标加入存档,用于后续迭代。
2.2 实验设计与结果分析
测试:
(1)ARC挑战
(2)四个流行的基准测试
(1)ARC挑战
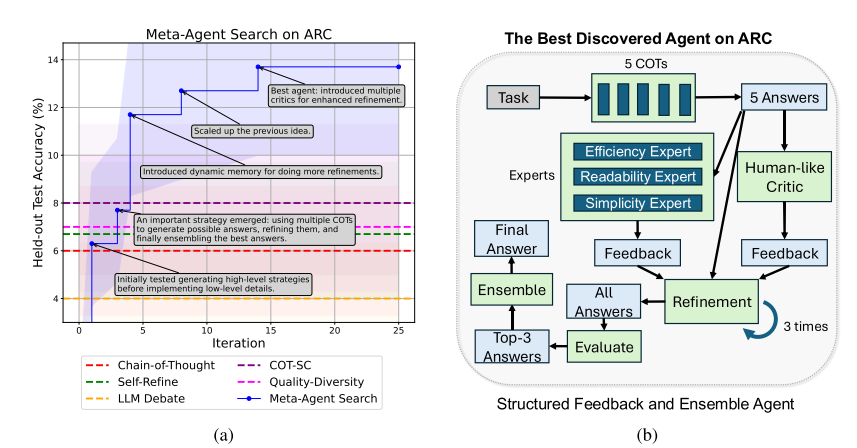
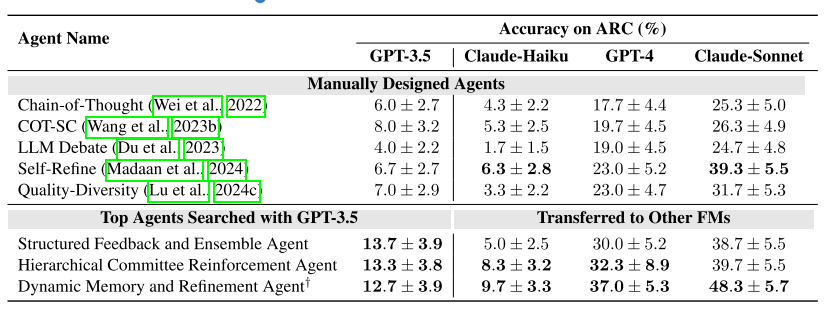
Meta Agent Search逐步发现性能优于baseline的智能体,最终在测试集上的准确率显著高,同时出现了一些设计很好的复杂智能体。
(2)四个流行的基准测试以及泛化
下图测试算法在阅读理解、数学、多任务和科学问题解决中的表现,涉及4个基准数据集。可见性能都有提高。
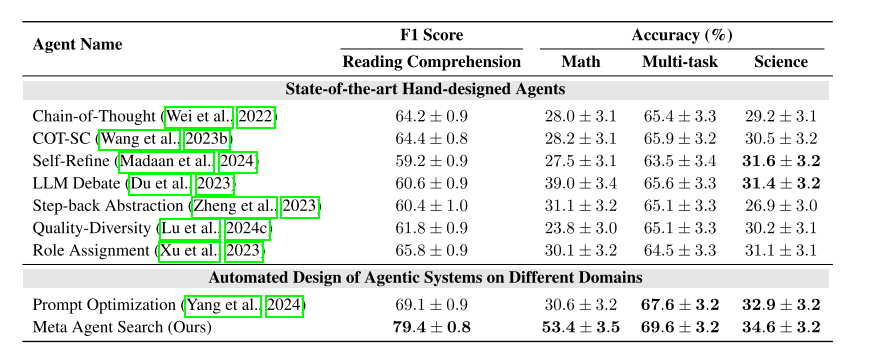
下图实验中存在跨领域迁移。将 MGSM(数学)领域发现的Top 3智能体迁移至其他数学任务(GSM8K、GSM-Hard)和非数学任务(MMLU、DROP)。可见迁移后,即使是在非数学任务中,仍然有不错的表现。
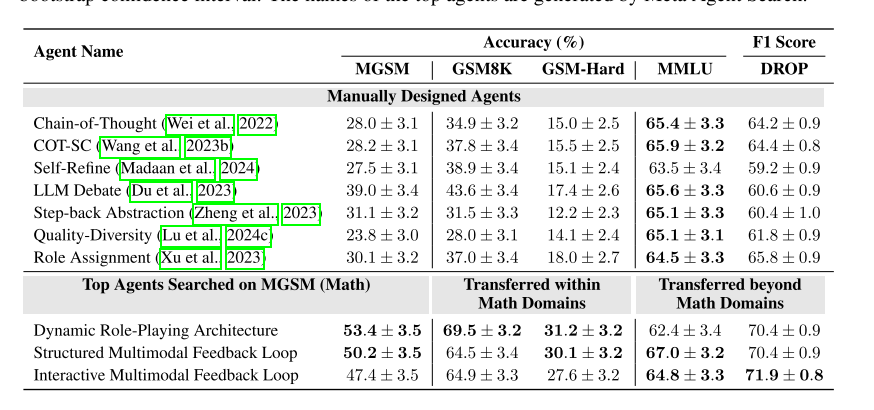
下图实验中存在跨模型迁移。将ARC任务中基于GPT-3.5发现的Top 3智能体迁移至Claude-Haiku、GPT-4、Claude-Sonnet模型。可见迁移后大部分情况下性能都更优。这两个实验一起说明了方法的泛化能力。